Here’s how developers can implement the Google Translate API in their apps
Even if most of us can’t travel as we once did, the world is a more accessible place, at least online. Business people may not be attending international conferences or flying around the world for meetings so much. But in many respects, businesses are finding that they can access and develop foreign markets by localizing their websites and apps to speak the language of locals and adapt to their standards. Developers can play an integral role in the localization process.
How localization tools are driving innovation in AI-driven APIs
Developers can hop on this trend, increase the value of their software, and expand online on capabilities to their apps. Google has emerged as a leader in translation algorithms in the past decade, leveraging advances in AI-driven neural network tech . This powers Google Translate, well-known to businesses for their companies or clients. They can do so readily by adding auto-translators Google Translate, well-known to businesses and consumers, an app that has made an impact on the translation profession as we know it. We’ll explore here how developers can add Google-powered translations to their apps by leveraging the powers of the company’s Translate API. Localization tools, which drive greater accuracy in translation mechanics, are also necessary for the translator to work more efficiently.
Before diving into the software weeds, it’s worth noting alternatives to the Google Translate API route. Third-party conversion tools like Zapier and IFTTT let you link your software workflow to auto-translation modules via webhooks and web services, with a minimum of coding. Even a tech-savvy non-programmer should be able to implement these solutions. The main drawback, however, is that you are likely to settle for a translation engine inferior to the one offered by Google.
What does Google offer for translation?
Google is a pioneer in both machine language and machine learning—the two L-words representing two sides of the same coin. Language needs to be learned, and that learning is achievable by mastery of a natural language. AI-driven mastery these days is driven by neural machines or NMT in 2016, bringing a “paradigm shift” in translation tech. From that year forward, NMT has been the preferred method of translating.
Back in 2006, Google started training its translation algorithm by digesting tens of millions of words extracted from translated documents of the European Union parliament and the United Nations. Today Google confronts competition from Facebook, which is leveraging the learnings from comments and posts by its 2 billion users to translate more casual conversations, including rendering LOL and WTF in scores of languages. NMT continues to be a way to go.
Happily, the language learning process didn’t stop with bureaucratese and Emoji. Google Translate today supports over 100 languages, several dozen with voice support. You can talk in one language and get the translation vocalized in another, usually with a choice of voice. And, as we will see, machine learning has been productized so that you can effectively translate a domain-specific language of your own.
Getting started with Google Translate API
Google promotes its API as fast and dynamic, adaptable to diverse content needs. The company markets not just to professional coders but to a broader spectrum of users, including those with “limited machine learning expertise” who can quickly “create high-quality, production-ready models.”
For the latter, you can just upload translated language pairs (a structured list of words/phrases with their translations) and AutoML Translation will train a custom translation model. The workflow allows either customized-by-the-client or pre-trained (by Google) inputs. To translate an English product description into French, Korean, and Portuguese, for example, you could customize a Google AutoML model for French and rely on an off-the-shelf pre-trained model for Korean and Portuguese. Then you simply upload your English HTML file to Google Cloud Storage and send a batch request to the Translation API pointing to your AutoML and the pre-trained models. Google’s AutoML Translation will then output your HTML in three separate language files to your Cloud Storage.
Training is key, but the initial model is pre-trained to render 100+ languages. And if you have a domain-specific lexicon (medical or legal terms, for example) these require just a little more training and tweaking of the basic API, if they don’t already exist. A Glossary lets users “wrap” proprietary terminology not to be translated (like brand and product names) to ensure they stay intact during translation. There is also built-in support Media Translation API, which handles real-time, low latency streaming of audio translations.
The process is essentially three steps: Upload a language pair. Train AutoML. Evaluate.
This translation power is not free but the pricing is fair. Typically, you’ll be using Google’s Translate API and its Media Translation API (if you need voice support). You’ll need the AutoML service only if you need to train more language pairs.
The fee for the Translate API is $20 per million characters. The Media Translation API will set you back $0.068 to $0.084 per minute. AutoML is a bit pricier, costing $45 per hour for training a language pair, to a max of $300/pair. Pay only for what you use, as you use it. (Google is patient: it wants to get you hooked, so it throws in free processing as you get up to speed, with a full year to practice before needing to pay up.)
Setting up for Your First Translation
The RESTful Translate API is the easiest way to get started. Google offers a basic and advanced setup. You can do this with localization tools, but you can also do it manually. If you’ve set up any Google API service, you’re probably comfortable with the drill and may already have a Cloud Console Account. Assuming this is true, the next things you need to do, if you haven’t already, are:
Create or select your project.
Enable the Cloud Translation API.
Create a service account.
Download your private key in JSON format. Keep the full path to this file for the next step.
Go to the shell prompt on your Mac OS X, Linux, or Windows (Powershell) system and set the environment variable GOOGLE_APPLICATION_CREDENTIALS to the path of your JSON service account key using the following commands. This variable only applies to the current shell session. If you open a new session, you’ll need to reset this variable, replacing [PATH] with the path of the JSON file with your key.
If you’re using Linux or macOS:
For Windows, in PowerShell:
Or, from a command prompt:
Then install and initialize Google’s Cloud SDK. Depending on which operating system you’re using, the Cloud SDK may have a dependency on a version of Python that isn’t installed on your system. So be sure to double-check the Cloud SDK documentation to ensure the appropriate version of Python is installed.
Executing Your First Translation
Make a Translation API Request with a REST call using the v2 translate method.
Use curl to make your request to the https://translation.googleapiom/language/translate/v2 endpoint.
The command includes JSON with (1) the text to be translated (q), (2) the language to translate from (source), and (3) the language to translate to (target).
Source and target languages are identified with ISO-639-1 codes. In this example, the source language is English (en), the target is French (fr). The query format is plain “text”.
The sample curl command uses the gcloud auth application-default print-access-token command to get an authentication token.
The response should resemble the following:
Congratulations! You’ve sent your first request to the Cloud Translation API!
Next steps in the translation process
For most apps, you can rely on one of the over 100 language pairs already trained and tested. (If the pair you require is not available, or you need a custom translation with the AutoML training module.) The full process is as follows:
Client libraries are currently available for seven popular programming languages – C#, Go, Java, Node.js, PHP, Python, and Ruby. Just install the library of your choice. Go to Translation Client Libraries for installation instructions.
This article was originally published by Richard Koret on TechTalks , a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech, and what we need to look out for. You can read the original article here .
Scientists figured out how to turn black holes into power sources
A group of scientists from Columbia University recently published a paper detailing how humanity could power an off-Earth colony by tapping into one of the universe’s largest and most powerful resources: black holes.

The big idea here is that a spinning black hole gives off a certain amount of energy. If we enveloped this energy field with an external gravity source (a big gravity gun?) we could force the singularity to generate negative energy. This negative energy would, theoretically, sort of switch places with some escaping positive energy, thus freeing it from the black hole’s hungry grasp and making it available for use as a power source.
[Read next: How Netflix shapes mainstream culture, explained by data ]
Basically, we’d turn a black hole into a perpetual battery. This could be very useful for any future Earthlings planning to live on another planet or in a deep space station. Currently we don’t have any solid methods for keeping things going in space.
Per the team’s research paper :
Quick take: This is super cool. Realistically, Dyson Spheres and other stellar-based theories have always seemed like the most likely method by which we’d perpetually power off-world colonies. But this alternative actually seems… easier? It stands to reason it would take less gear to siphon energy out of a black hole than it would to enshroud a star with a mechanism for energy conversion. This, of course, is all speculative since we’re not quite at the blueprint phase of these hypothetical machines.
From an engineering/computer science point of view, however, getting power from a singularity could be a nightmare. We’d likely be forced to operate the ‘power sucker,’ just outside of the event horizon of the singularity. It’s a no-brainer that we’d need quantum computing algorithms far more robust than today’s cutting edge to handle that kind of math. And figuring out how to deal with unpredictable blasts of energy, in the physical, material sense, would be an incredible challenge.
The researchers clearly demonstrate that siphoning energy from a spinning black hole is possible, but we all know there’s no such thing as a free lunch when it comes to energy exchange, at least not with current technology.
The good news is: by the time we’re able to get humans close enough to a black hole to build this kind of near-infinite battery backup for space colonies, we’ll likely be able to come up with stronger AI and more robust physical materials.
Check out the full paper here in the APS Physics journal.
Bollywood movies continue to associate beauty with fair skin, AI study finds
Bollywood continues to associate female beauty with fair skin, according to a new AI study by Carnegie Mellon University computer scientists.

The researchers explored evolving social biases in the $2.1 billion film industry by analyzing movie dialogues from the last 70 years.
They first selected 100 popular Bollywood films from each of the past seven decades, along with 100 of the top-grossing Hollywood movies from the same period.
They then applied Natural Language Processing (NLP) techniques to subtitles of the films to examine how social biases have evolved over time.
“Our argument is simple,” the researchers wrote in their study paper . “Popular movie content reflects social norms and beliefs in some form or shape.”
The researchers investigated depictions of beauty in the movies by using a fill-in-the-blank assessment known as a cloze test.
They trained a language model on the movie subtitles, and then set it to complete the following sentence:
While the base model they used predicted “soft” as the answer, their fine-tuned version consistently selected the word “fair.”
The same thing happened when the model was trained on Hollywood subtitles, although the bias was less pronounced.
The researchers attribute the difference to “the age-old affinity toward lighter skin in Indian culture.”
Evolving trends
The study also evaluated the prevalence of female characters in films by comparing the number of gendered pronouns in the subtitles.
The results indicate that the progress towards gender parity in both Hollywood and Bollywood has been slow and fluctuating
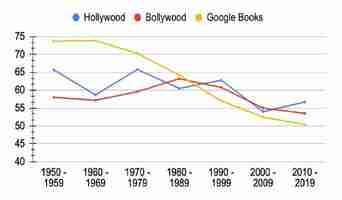
The male pronoun ratio in both film industries had dipped far less over time than a selection of Google Books. The researchers also analyzed sentiments about dowry in India since it became illegal in 1961 by analyzing the vocabulary with which it was it was connected in the films.
They found words including “loan,” “debt,” and “jewelry” in movies of the 1950s, suggesting compliance with the practice. But by the 2000s, the words most closely associated with dowry were more negative examples, such as “trouble,” “divorce,” and “refused,” indicating non-compliance or more gloomy consequences.
“All of these things we kind of knew, but now we have numbers to quantify them,” said study co-author Ashiqur R. KhudaBukhsh. “ And we can also see the progress over the last 70 years as these biases have been reduced.”
The study shows that NLP can uncover how popular culture reflects social biases. The next step could be using the tech to show how popular culture influences those biases.