Why applied AI requires skills and knowledge beyond data science
Every year, machine learning researchers fascinate us with new discoveries and innovations. There are a dozen artificial intelligence conferences where researchers push the boundaries of science and show how neural networks and deep learning architectures can take on new challenges in areas such as computer vision and natural language processing.

But using machine learning in real-world applications and business problems—often referred to as “applied machine learning” or “applied AI”—presents challenges that are absent in academic and scientific research settings. Applied machine learning requires resources, skills, and knowledge that go beyond data science, that can integrate AI algorithms into applications used by thousands and millions of people every day.
Alyssa Simpson Rochwerger and Wilson Pang, two experienced practitioners of applied machine learning, discuss these challenges in their new book Real World AI: A Practical Guide for Responsible Machine learning . Rochwerger, a former director of product at IBM Watson, and Pang, the CTO of Appen, draw on their personal experience and knowledge to provide many examples of how organizations succeeded or failed in integrating machine learning into their products and business models.
Real World AI explains the common challenges and pitfalls of machine learning strategies and how product leaders can avoid repeating the failures of other organizations. Here are four of the key challenges that Rochwerger and Pang highlight in their book.
Defining the problem
Knowing the problem you want to solve is a challenge that applies to all software engineering tasks. Any experienced developer will acknowledge that “doing the right thing” is different from “doing the thing right.” In applied machine learning, defining the problem plays a crucial role in the choices you make for the technologies, data sources, and people who will be working on your product.
“Only 20 percent of AI in pilot stages at major companies make it to production, and many fail to serve their customers as well as they could,” Rochwerger and Pang write in Real World AI . “In some cases, it’s because they’re trying to solve the wrong problem. In others, it’s because they fail to account for all the variables—or latent biases—that are crucial to a model’s success or failure.”
Consider image classification problems. Deep neural networks can perform such tasks with stunning accuracy. But if you want to apply them to a real application, a detailed definition of the problem will determine the kind of model, data, talent, and investment you’ll need.
For instance, if you want a neural network that can label the files in your image archive, there are plenty of pre-trained convolutional neural networks (e.g., ResNet, Inception) and public datasets (e.g., ImageNet and Microsoft COCO) that you can use out of the box. You can set up the deep learning model on your own server and run your images through it. Alternatively, you can sign up for an API-based service such as Amazon Rekognition or Microsoft Azure Computer Vision. In this case, inference will be done in the service provider’s servers.
But suppose you’re working for a large agriculture company and want to develop an image classifier that runs on drones and can detect weed in crops. Hopefully, the technology will help your company switch to precision application of herbicide to cut down costs, waste, and the negative effects of chemicals. In this case, you’ll need a more specialized approach. You’ll have to consider constraints on the machine learning model and the data. You need a neural network that is light enough to run on the compute resources of edge devices. And you’ll need a special dataset of labeled images of weed vs non-weed plants.
In machine learning, defining the problem also includes determining how well you want to solve the problem. For example, in the case of image archive labeling, if your machine learning model mislabels five of every hundred images, you shouldn’t have much of a problem. But if you’re creating a cancer-detection neural network, then you’ll need a much higher standard. Every missed case can have life-impacting consequences.
Gathering training data
One of the key challenges of applied machine learning is gathering and organizing the data needed to train models. This is in contrast to scientific research where training data is usually available and the goal is to create the right machine learning model.
“When creating AI in the real world, the data used to train the model is far more important than the model itself,” Rochwerger and Pang write in Real World AI . “This is a reversal of the typical paradigm represented by academia, where data science PhDs spend most of their focus and effort on creating new models. But the data used to train models in academia are only meant to prove the functionality of the model, not solve real problems. Out in the real world, high-quality and accurate data that can be used to train a working model is incredibly tricky to collect.”
In many applied machine learning applications, public datasets are not useful for training models. You need to either gather your own data or buy them from a third party. Both options have their own set of challenges.
For instance, in the herbicide surveillance scenario mentioned earlier, the organization will need to capture a lot of images of crops and weeds. For the machine learning model to work reliably, the engineers will need to have to take the photos under different lighting, environmental, and soil conditions. After gathering the data, they’ll need to label the images as “plant” or “weed.” Data labeling requires manual effort and is a tiring job and has given rise to an entire industry of its own. There are dozens of platforms and companies that provide data labeling services for AI applications.
In other settings, such as healthcare and banking, the training data will contain sensitive information. In such cases, outsourcing labeling tasks can be tricky, and the product team will have to be careful not to run afoul of privacy and security regulations.
Yet in other applications, the data might be fragmented and scattered across different databases, servers, and networks. When organizations are drawing data from various sources, they’ll face other challenges too, such as inconsistency between database schemas, mismatching conventions, missing data, outdated data, and more. In such cases, one of the main challenges of the machine learning strategy will be to clean the data and consolidate different sources into a data lake that can support the training and maintenance of the ML models.
In cases where the data comes from different databases, verifying data quality and provenance is also crucial to the quality of machine learning models. “It’s incredibly common in an enterprise to find data scattered throughout databases in different departments without any documentation about where it’s from or how it got there,” Rochwerger and Pang warn. “As data makes its way from the point where it’s collected into the database where you find it, it’s very likely that it has been changed or manipulated in a meaningful way. If you make assumptions about how the data you’re using got there, you could end up producing a useless model.”
Machine learning models are prediction machines that find patterns in data obtained from the world and forecast future outcomes from current observations. As the world around us changes, so do the data patterns, and models trained on past data gradually decay.
“AI isn’t a ‘set it and forget it’ type of system that will keep churning out results without human intervention. It requires constant maintenance, management, and course-correction to continue to provide meaningful, desired output,” Rochwerger and Pang write in Real World AI.
A stark example was the covid-19 pandemic, which caused a worldwide lockdown and changed many living habits, which disrupted many machine learning models . For instance, as shopping transitioned from brick-and-mortar to online stores, machine learning models used in supply chain management and sales forecasting became obsolete and needed to be retrained.
Therefore, a key part of any successful machine learning strategy is making sure you have the infrastructure and processes to collect a continuous stream of new data and update your models. In case you’re using supervised machine learning models , you’ll also have to figure out how to label the new data. In some cases, you can do this by providing tools that allow users to provide feedback on the predictions made by the machine learning models. In others, you’ll need to label new data manually.
“Don’t forget to allocate resources for the ongoing training of your model. Models have to be trained continually, or they’ll become less accurate over time as the real world changes around them,” Rochwerger and Pang write.
Gathering the right team
In applied machine learning, your models will affect people’s work and life (and your company’s bottom line). And that’s why an isolated team of data scientists will seldom implement a successful machine learning strategy.
“A business problem that can be solved by a model alone is very unusual. Most problems are multifaceted and require an assortment of skills—data pipelines, infrastructure, UX, business risk analysis,” Rochwerger and Pang write in Real World AI . “Put another way, machine learning is only useful when it’s incorporated into a business process, customer experience or product, and actually gets released.”
Applied machine learning needs a cross-functional team that includes people from different disciplines and backgrounds. And not all of them are technical.
Subject matter experts will need to verify the veracity of training data and the reliability of the model’s inferences. Product managers will need to establish the business objectives and desired outcomes for the machine learning strategy. User researchers will help to validate the model’s performance through interviews with and feedback from end-users of the system. And an ethics team will need to identify sensitive areas where the machine learning models might cause unwanted harm.
“The non-technical components of a successful AI solution are just as important, if not more important, than the purely technical skills necessary to build a model,” Rochwerger and Pang write.
Applied machine learning also needs technical support beyond data science skills. Software engineers will have to help integrate the models into other software being used by the organization. Data engineers will need to set up the data infrastructure and plumbing that feed the models during training and maintenance. And the IT team will need to provide the compute, network, and storage resources needed to train and serve the machine learning models.
“Even with a wonderful business strategy, a well-articulated, specific problem, and a great team, it’ll be impossible to achieve success without access to the data, tools, and infrastructure necessary to ingest each dataset, save it, move it to the right place, and manipulate it,” Rochwerger and Pang write.
Developing the right machine learning strategy
These were just some of the key challenges you’ll face in applied machine learning. You still need more elements to make your machine learning strategy work. In their book, Rochwerger and Pang discuss pilot programs, the “build vs buy” dilemma, dealing with production challenges, security and privacy issues, and the ethical challenges of applied machine learning. They provide plenty of real-world examples that show how you can do things right and avoid botching your machine learning initiative.
“There’s no reason to be afraid of AI. It’s not magic, and it’s not even rocket science. With hard work and the right team working together collaboratively, you can do this, and you can do it well,” Rochwerger and Pang write.
This article was originally published by Ben Dickson on TechTalks , a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech, and what we need to look out for. You can read the original article here .
Microsoft partners with GM to make self-driving cars a reality
Driverless car startup Cruise, a GM subsidiary, today announced the finalization of a two-billion dollar equity fund from primary investors Microsoft, Honda, and GM.

Leading off: Microsoft’s money is the big ticket item here for Cruise. While the company’s valuation has skyrocketed to about $20 billion from investors, netting one of big tech’s trillion-dollar whales has pushed GM stocks up nearly seven percent .
But the cash isn’t the only thing in play here. Per a Reuters report , Microsoft CEO Satya Nadella says the company will provide cloud services for Cruise:
Background: Microsoft Azure is quietly becoming a juggernaut. Not only did the big M beat out Amazon for the US government’s Project Jedi contract , it’s also recently entered into a $2 billion contract with OpenAI for cloud services and purchased GitHub .
This type of wheeling and dealing is nothing new for Microsoft, but the timing is interesting.
Quick take: Google’s toiled in the self-driving vehicle space for years with sister company Waymo seemingly perpetually on the brink of commercialization. Unfortunately the market hasn’t quite panned out as quickly as investors had hoped. Between COVID-19 and the unrealistic expectations set when deep learning exploded into the mainstream between 2014 and 2018, we’ve yet to see a single self-driving vehicle licensed for unrestricted use on roadways.
Microsoft’s likely pressing market advantage in a time when AI makers are sort of between big moments. The 2018 hype has died down and driverless cars are no longer just a few months away from commercialization.
The current state of the market has Telsa veering wildly to the left as it continues to attempt to brute force driverless vehicles without the aid of LIDAR or similar systems. Meanwhile Cruise, Waymo and a handful of other companies continue working on more robust systems in the hopes of solving self-driving AI.
That being said, there’s nothing like some good old fashioned competition to spark innovation. Now that Cruise has even bigger backing than just GM, there’s reason for optimism.
‘Bat-sense’ algorithm could be used to monitor people and property without cameras
A “bat-sense” algorithm that generates images from sounds could be used to catch burglars and monitor patients without using CCTV, the technique’s inventors say.

The machine-learning algorithm developed at Glasgow University uses reflected echoes to produce 3D pictures of the surrounding environment.
The researchers say smartphones and laptops running the algorithm could detect intruders and monitor care home patients.
Study lead author Dr Alex Turpin said two things set the tech apart from other systems:
The system analyses sounds emitted by speakers or radio waves pulsed from small antennas. The algorithm measures how long it takes for these signals to bounce around a room and return to the sensor.
It then analyzes the signal to calculate the shape, size, and layout of the room, as well as pick out the presence of objects or people. Finally, the data is converted into 3D images that are displayed as a video feed.
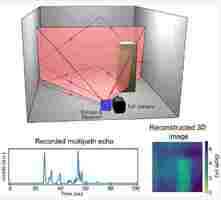
The system functions in a similar way to how bats use echolocation to navigate and hunt. The mammals send out sound waves that bounce back when they hit an object. The bats then interpret the echoes to determine the object’s location, size, and the direction (if any) that it’s moving.
The researchers believe their algorithmic recreation of this natural ability could greatly reduce the cost of 3D imaging.
You can read the research paper in the journal Physical Review Letters .
Greetings Humanoids! Did you know we have a newsletter all about AI? You can subscribe to it right here .